이전까지는 원리와 이해를 위한 글을 정리했었는데
이번에는 실제 사용하는 방법과 비슷하게 구현을 해보겠다.
2022.07.05 - [Studying/Machine Learning] - [머신러닝] Linear regression(선형 회귀) 구현
사용 모델은 linear regression과 이를 이용한 MLP다.
Linear Regression은 위 포스트를 참고하면 된다.
Pytorch에서 모델을 학습시키는 프로세스는 크게 3단계로 나뉜다.
1. 모델에 맞게 데이터 전처리
2. 모델 설계
3. 모델 학습
이 과정을 Mnist dataset(손으로 쓴 숫자 이미지)을 활용해서 진행해보겠다.
우선 패키지를 import 하겠다.
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
sklearn에 있는 mnist dataset을 가져오겠다.
mnist = fetch_openml('mnist_784', cache=False)
mnist.data.shape
# (70000, 784)mnist의 각 이미지는 28*28 pixel로 이루어져 있어서 이를 펼친 784차원의 벡터로 되어있다.
각 픽셀은 0~255의 값으로 흰색과 검은색 사이 값을 나타낸다.
target에는 각 이미지의 실제 숫자 값이 들어있다.
Data Preprocessing
데이터의 값을 추출해서 X와 y에 담는다.
X = mnist.data.astype('float32')
y = mnist.target.astype('int64')
X = X.values
y = y.values
print(X.shape) # (70000, 784)
print(y.shape) # (70000)
먼저 X의 데이터를 0~1의 값으로 scaling 해주겠다.
X /= 255.0
학습과 평가를 위한 dataset으로 나눈다.
sklearn의 train_test_split을 사용하겠다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_val, X_test, y_val, y_test = train_test_split(X_test, y_test, test_size=0.5)모든 데이터에서 train 80퍼센트, test와 validation 각각 10퍼센트로 나눠준다.
총 70000개였으니 56000, 7000, 7000개로 나뉜다.
위의 Dataset을 다루기 위해 class를 선언한다.
가장 보편적인 torch.utils.data.Dataset을 상속받아서 사용하겠다.
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
super(CustomDataset, self).__init__()
self.X = X
self.y = y
def __getitem__(self, index):
x = self.X[index]
y = self.y[index]
x = torch.from_numpy(x).float()
y = torch.from_numpy(np.array(y)).long()
return x, y
def __len__(self):
return len(self.X)이 내용은 아래 포스트에서 확인할 수 있다.
2022.06.06 - [Studying/Python] - [Python] 웹 크롤링 데이터 클래스를 사용해 구조화해서 접근하기
각 dataset을 할당해주겠다.
train_dataset = CustomDataset(X_train, y_train)
val_dataset = CustomDataset(X_val, y_val)
test_dataset = CustomDataset(X_test, y_test)
이제 batch를 sampling하기 위해 dataloader을 사용하겠다.
필수 옵션은 다음과 같다.
dataset : sampling 할 dataset
batch_size : 한번에 sampling 할 데이터 개수
shuffle : 1 epoch 기준으로 shuffle 할지 여부
batch_size = 64
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)DataLoader의 추가적인 옵션들은 아래 document를 참고하면 된다.
https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
torch.utils.data — PyTorch 1.12 documentation
torch.utils.data At the heart of PyTorch data loading utility is the torch.utils.data.DataLoader class. It represents a Python iterable over a dataset, with support for These options are configured by the constructor arguments of a DataLoader, which has si
pytorch.org
이제 데이터 전처리가 끝났다.
Model
Pytorch에서 model을 선언할 때는 torch.nn.Module을 상속받아 init()과 forward() 함수를 작성해준다.
init에는 모델의 파라미터들을 선언하고 forward에는 파라미터를 이용해 data를 모델에 통과시켜준다.
그럼 Linear Regression(LR) 모델과 MLP모델을 initialize 하겠다.
class LR(nn.Module):
def __init__(self, input_dim, output_dim):
super(LR, self).__init__()
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, x):
x = self.fc(x)
return x
class MLP(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return xMLP모델은 linear 레이어를 거치고 relu함수를 통과시킨 뒤 linear 레이어를 한번 더 통과시키는 모델로 구현했다.
이번 포스트에서 Relu함수는 더보기로 간단하게 보여주고 나중에 활성화 함수들을 한 번에 정리하겠다.
Relu 함수
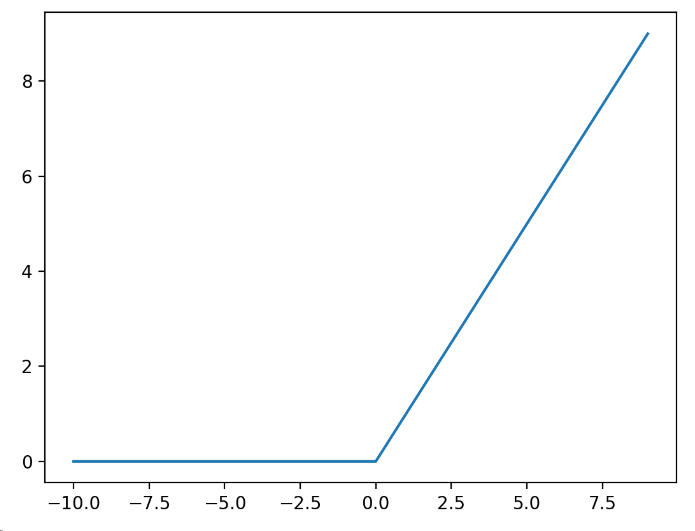
Relu 함수는 이렇게 0 이하의 값은 0으로 없애고 0 이상의 값은 남기는 함수이다.
sigmoid에서 gradient값이 사라지는 현상(vanishing gradient)을 막기 위해 나오게 되었다.
Training
이제 모델을 학습시켜보자.
학습을 진행하기 위해 model의 파라미터를 최적화할 optimizer가 필요하다.
가장 보편적으로 사용되는 Adam optimizer를 사용하겠다.
training을 위한 class를 정의하겠다.
class Trainer():
def __init__(self, trainloader, valloader, testloader, model, optimizer, criterion, device):
self.trainloader = trainloader
self.valloader = valloader
self.testloader = testloader
self.model = model
self.optimizer = optimizer
self.criterion = criterion
self.device = device
def train(self, epoch = 1):
self.model.train()
for e in range(epoch):
running_loss = 0.0
for i, data in enumerate(self.trainloader, 0):
inputs, labels = data
# model의 input과 output을 gpu-device로 보낸다
inputs = inputs.to(self.device)
labels = labels.to(self.device)
# gradient를 0으로 초기화해준다.
self.optimizer.zero_grad()
# input을 model에 통과시켜 output을 받는다.
outputs = self.model(inputs)
# loss function을 사용해 model의 loss를 구한다.
loss = self.criterion(outputs, labels)
# loss를 통해 backpropagation을 한다.
loss.backward()
# gradient descent를 통해 model의 output을 얻는다.
self.optimizer.step()
running_loss += loss.item()
print('epoch: %d loss: %.3f' % (e + 1, running_loss / len(self.trainloader)))
running_loss = 0.0
val_acc = self.validate()
return val_acc
def validate(self):
self.model.eval()
correct = 0
for inputs, labels in self.valloader:
inputs = inputs.to(self.device)
labels = labels.to(self.device)
output = self.model(inputs)
pred = output.max(1, keepdim=True)[1] # get the index of the max
correct += pred.eq(labels.view_as(pred)).sum().item()
return correct / len(self.valloader.dataset)
def test(self):
self.model.eval()
correct = 0
for inputs, labels in self.testloader:
inputs = inputs.to(self.device)
labels = labels.to(self.device)
output = self.model(inputs)
pred = output.max(1, keepdim=True)[1] # get the index of the max
correct += pred.eq(labels.view_as(pred)).sum().item()
return correct / len(self.testloader.dataset)
먼저 Linear regression만 사용해 학습해보겠다.
Linear Regression
input_dim = 784
output_dim = 10
epoch = 4
device = torch.device('cuda')
best_acc = 0.0
lrs = [1e-1, 1e-2, 1e-3, 1e-4]
for lr in lrs:
model = LR(input_dim=input_dim, output_dim=output_dim).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
trainer = Trainer(train_dataloader, val_dataloader, test_dataloader, model, optimizer, criterion, device)
val_acc = trainer.train(epoch = epoch)
print('val_acc: %.3f' %(val_acc))
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), './best_model')
trainer.model.load_state_dict(torch.load('./best_model'))
test_acc = trainer.test()
print('test_acc: %.3f' %(test_acc))약 92 퍼센트의 정확도가 나왔다.
MLP (Linear + Relu + Linear)
input_dim = 784
hidden_dim = 32
output_dim = 10
epoch = 4
device = torch.device('cuda')
best_acc = 0.0
lrs = [1e-1, 1e-2, 1e-3, 1e-4]
for lr in lrs:
model = MLP(input_dim=input_dim,
hidden_dim=hidden_dim,
output_dim=output_dim).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
trainer = Trainer(train_dataloader, val_dataloader, test_dataloader, model, optimizer, criterion, device)
val_acc = trainer.train(epoch = epoch)
print('val_acc: %.3f' %(val_acc))
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), './best_model')
trainer.model.load_state_dict(torch.load('./best_model'))
test_acc = trainer.test()
print('test_acc: %.3f' %(test_acc))
약 96퍼센트의 정확도가 나왔다.
이렇게 Mnist 데이터를 이용해 데이터 전처리, 모델 선택, 학습, 테스트까지 해봤다.
'Studying > Machine Learning' 카테고리의 다른 글
| [머신러닝] Convolutional Neural Network 이해하기 (2) | 2022.07.21 |
|---|---|
| [머신러닝] Activation function(활성화 함수) 정리 (2) | 2022.07.19 |
| [머신러닝] K-Means Clustering - 물고기 데이터셋 (0) | 2022.07.18 |
| [머신러닝] K-Means Clustering 정리 (0) | 2022.07.15 |
| [머신러닝] Overfitting & Regularization (with Polynomial function) (0) | 2022.07.12 |




댓글