이전 포스트까지는 input, output이 정해져 있고 이 둘의 관계를 잘 설명하는 model을 학습시켜왔다.
이렇게 아웃풋(target)이 정해져 있고 학습에 이걸 사용하는 것을 supervised learning(지도 학습)이라고 한다.
이런 아웃풋을 정하지 않고도 학습하는 방법이 있다.
이를 unsupervised learning(비지도학습)이라고 한다.
이 방법 중 하나인 K-Means Clustering에 대해 정리해보려고 한다.
K-Means Clustering
K-Means Clustering은 분류가 되어있지 않은 데이터들을 다룰 때 사용한다.
미리 정해놓은 개수의 클러스터로 주어진 데이터를 묶는 방법이다.
데이터를 반복적으로 k개의 클러스터 중 하나로 할당하는 방법의 학습이 진행된다.
결국 가까운 데이터들끼리 같은 클러스터에 할당되게 된다.

Process
K-Means Clustering은 데이터들을 각 클러스터의 중심(centroid)을 기준으로 clustering을 한다.
process는 먼저 데이터를 가장 가까운 centroid의 cluster에 배정한다.
이렇게 각 data가 cluster에 배정되었다면 각 cluster에 속한 data의 평균 위치로 centroid가 갱신된다.
더 이상 cluster의 data가 변하지 않을 때까지 반복을 한다.
이 알고리즘은 반드시 수렴하게 되어 있지만 초기화 방식에 따라 local optimum으로 수렴할 수도 있다고 한다.
Elbow method
그러면 K를 어떻게 설정할지 찾아야 한다.
이번 포스트에서는 elbow method를 보겠다.
elbow method는 여러 가지 k에 대해 모두 실험을 해보고 그 cost function을 그래프로 표현한 뒤 k값을 찾는다.
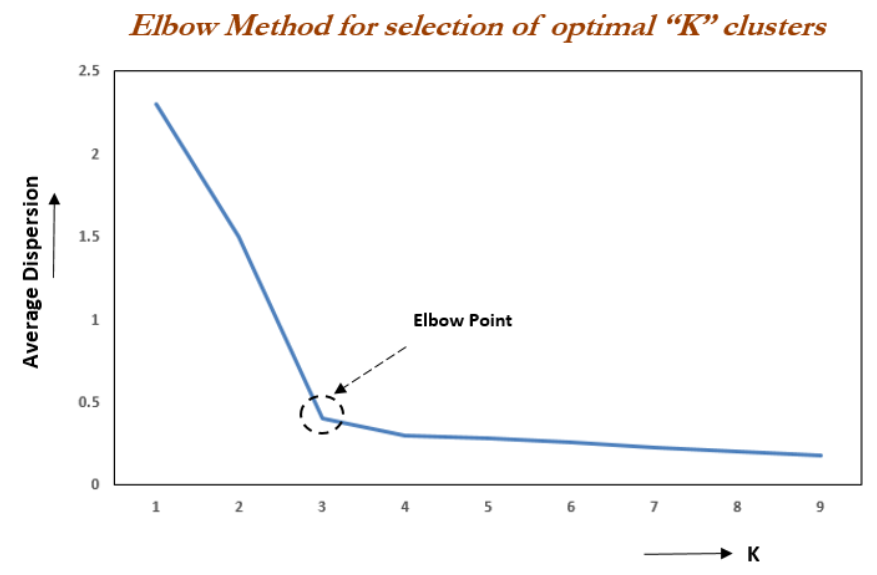
위 그래프에서 k가 커질수록 cost가 줄어드는데 k를 그냥 키우기만 한다면 clustering의 의미가 사라지게 된다.
그래서 기울기가 급변하는 지점의 k를 선택하게 되고 이 부분이 팔꿈치와 같은 모양이라 elbow function이라 부른다.
다음 포스트에서는 이 방법을 사용해서 실제 데이터를 분류해보겠다.
'Studying > Machine Learning' 카테고리의 다른 글
| [머신러닝] Pytorch Linear Regression & MLP - Mnist 활용 (8) | 2022.07.18 |
|---|---|
| [머신러닝] K-Means Clustering - 물고기 데이터셋 (0) | 2022.07.18 |
| [머신러닝] Overfitting & Regularization (with Polynomial function) (0) | 2022.07.12 |
| [머신러닝] Logistic Regression - 타이타닉 탑승자 사망여부 예측 (0) | 2022.07.11 |
| [머신러닝] Logistic Regression (0) | 2022.07.07 |




댓글